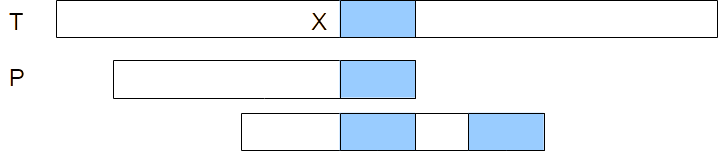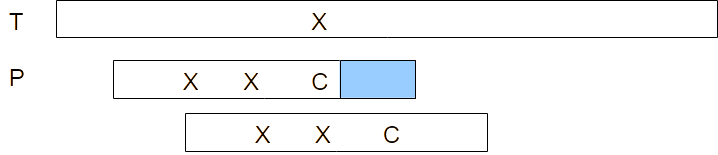
Bad character rule. Pattern P is matched to the text T starting from the right, the blue box representing the section of the pattern that matches the text, with a mismatch between characters C in the pattern and character X in the text. The third row represents a shift of the pattern such that the rightmost X in the pattern now matches with the X in the text.